Perché le applicazioni di intelligenza artificiale di largo consumo sono progredite così velocemente?

Nel primo post abbiamo visto che le applicazioni di intelligenza artificiale potrebbero trasformare l’assistenza sanitaria pediatrica a livello globale e locale. Stiamo assistendo a progressi rapidissimi delle applicazioni di intelligenza artificiale commerciali. Per esempio, le applicazioni di intelligenza artificiale sono in grado di riconoscere immagini comuni con maggiore precisione rispetto all’uomo. Come è stato ottenuto questo risultato?
Nel 2010, i ricercatori della Stanford University hanno lanciato una competizione chiamata ImageNet nella quale hanno costruito un database di 14 milioni di immagini di 856 tipi di uccelli, 993 tipi di alberi e 157 strumenti musicali. La competizione aveva l’obiettivo di verificare quanto potesse essere preciso un computer addestrato a riconoscere le immagini. Ci sono voluti solo cinque anni perché i computer diventassero più precisi dell’uomo. [1] [2] [3]

Come si può vedere nella figura qui sopra che illustra i vincitori della competizione per ogni anno, il team di Microsoft nel 2015, con una applicazione di intelligenza artificiale, è scesa sotto la soglia di errore umano. In che modo un’applicazione di intelligenza artificiale è stata in grado di superare l’uomo?
Reti neurali.
Sebbene le reti neurali siano state discusse a lungo nella letteratura scientifica dagli anni ’60 in poi, queste hanno raggiunto risultati di grande precisione solo recentemente, attraverso i progressi del cloud computing,
Come mostra il diagramma qui sopra (per gentile concessione di Jeff Dean, capo di Google Brain), il principio è semplicemente che maggiore è la potenza di calcolo e più numerosi i dati forniti, maggiore è il grado di accuratezza che le reti neurali sono in grado di raggiungere. Per quelli che vivono nelle principali aree metropolitane americane, questo è il motivo per cui molte auto dotate di diverse telecamere per la raccolta di dati, girano per la città. Quello che fanno queste auto è raccogliere quanti più dati possibile dal mondo reale per addestrare in modo più accurato le applicazioni di intelligenza artificiale per la guida autonoma.
Cos’è una rete neurale?
Le reti neurali possono assumere forme e strutture diverse, ma in sintesi sono costruite sul modello biologico del nostro cervello e sul modo in cui funzionano i nostri neuroni. Il grafico che segue mostra schematicamente l’elemento costitutivo di base di una rete neurale, un neurone.

In questo schema, i dati di input (x), vengono moltiplicati per un coefficiente (w) e sommati. Il risultato viene trasferito a una funzione di attivazione che si traduce in un output, che può essere inviato a un altro neurone. I dati di un’immagine, ad esempio, possono essere rappresentati come una matrice di valori di pixel, che possono essere inviati come input (x) a una rete neurale per la classificazione.
Una rete neurale è organizzata in diversi strati di neuroni. Si parla di deep learning quando vengono aggiunti sempre più livelli (livelli nascosti) oltre il primo livello. I modelli di deep learning possono avere centinaia di questi livelli nascosti.

L’esecuzione di una rete neurale (ovvero un’applicazione di intelligenza artificiale) consiste semplicemente nell’eseguire questo calcolo su un testo qualsiasi (come fa ChatGPT), un’immagine (come nell’esempio della diagnosi della displasia corticale focale del primo post) o una voce (ad esempio Siri).
Ovviamente il trucco è come addestrare una rete neurale in modo che sia accurata. Lo sviluppo di una rete neurale viene eseguito usando un set di dati che viene diviso in una parte di dati che viene usata per l’addestramento e un’altra parte per il test. Il set di dati per l’addestramento viene utilizzato per determinare i vari coefficienti (w) e il numero di strati di neuroni per raggiungere l’obiettivo. Una volta raggiunto un livello di precisione desiderato, si usa la parte dei dati di test per verificare che la rete neurale funzioni correttamente.
Nel caso di ImageNet, la competizione di Stanford, le informazioni provenienti dai singoli pixel delle immagini vengono analizzate dal primo strato di neuroni che trasmettono i segnali al secondo strato, che poi passa il risultato della sua analisi al terzo e così via. Ogni livello analizza concetti sempre più astratti come i bordi dell’immagine, le ombre e le forme, fino a quando lo strato di neuroni finale cerca di classificare l’intera immagine. Per raggiungere i diversi livelli di precisione nella competizione di ImageNet, ognuna delle squadre in gara ha provato diverse combinazioni nella struttura dei diversi strati e nelle funzioni di ponderazione per raggiungere crescenti gradi di precisione.
I progressi acquisiti sono stati realizzati su un’architettura centralizzata, che presuppone l’esistenza di un ampio database di immagini gestito centralmente. Nel caso di ImageNet, il database è composto da 150 GB di 4 milioni di immagini. Dato che un archivio centralizzato di un grande numero di immagini ha già dimostrato di essere importante per migliorare la capacità della rete neurale di riconoscerle e identificarle con precisione, non c’è da meravigliarsi se c’è interesse nell’applicare le lezioni apprese da ImageNet ad altre opportunità di riconoscimento delle immagini guidate dall’intelligenza artificiale. In ambito sanitario, un accesso a un grande numero di immagini da ecografie, risonanza magnetica, TC o radiografie potrebbe allo stesso modo servire a migliorare l’accuratezza con cui possiamo riconoscere e diagnosticare perfino condizioni rare come la displasia corticale focale. Molti sforzi sono in corso per sviluppare architetture centralizzate che raccolgono immagini standardizzate, interi database di immagini o data lake.
Tutto questo ha senso, vero? In realtà sì e no. Sì, per il desiderio di raccogliere più dati possibile. Ma l’accesso ai dati sanitari purtroppo non è facile. In effetti, i dati utilizzati per addestrare le applicazioni di intelligenza artificiale mediche per gli adulti provengono solo da pochi stati degli Stati Uniti e da un piccolo numero di paesi nel mondo. Tre stati (California, New York e Massachusetts) forniscono il 70% dei dati per l’addestramento di applicazioni di intelligenza artificiale ed è facile immaginare che questi dati non provengano dalle zone rurali della California.[4]
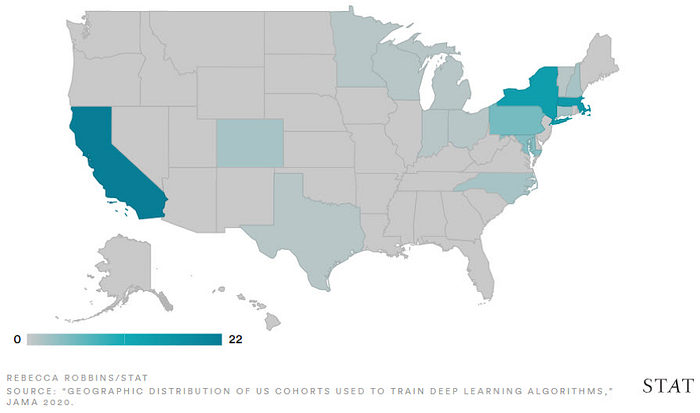
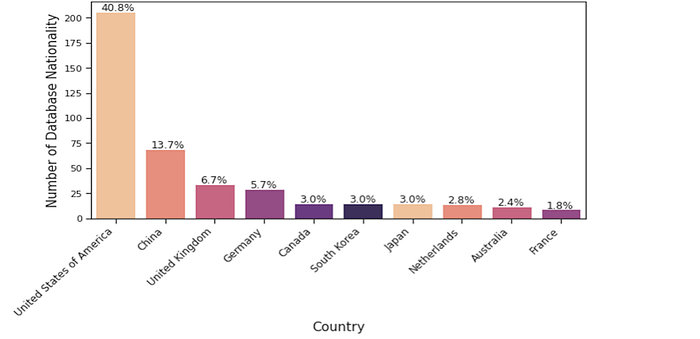
A livello globale, due paesi (Stati Uniti e Cina) forniscono oltre il 50% dei dati utilizzati per addestrare le applicazioni di intelligenza artificiale; solo otto dei restanti 193 paesi del mondo forniscono il resto dei dati.[5]
Il risultato è che molte applicazioni di intelligenza artificiale mancano di accuratezza in un’ampia varietà di popolazioni, o come ha concluso un recente articolo: “Quasi tutti gli studi pubblicati nel periodo di studio che hanno valutato le prestazioni degli algoritmi di intelligenza artificiale per l’analisi diagnostica delle immagini diagnostiche sono stati disegnati come studi di fattibilità e non disponevano dei requisiti raccomandati per una robusta validazione della performance clinica nel mondo reale dell’algoritmo di intelligenza artificiale [6].
In sintesi, mentre la raccolta centralizzata di set di dati sempre più grandi, unita all’aumento della potenza di calcolo, ha consentito ai software basati sulle reti neurali di raggiungere livelli di accuratezza crescenti, l’aggregazione di set di dati di grandi dimensioni in medicina si è dimostrata nel migliore dei casi problematica. Perché?
Special thanks to Alberto Tozzi, Head of Predictive and Preventive Medicine Research Unit at Ospedale Pediatrico Bambino Gesù for the translation to Italian. Also, thanks for extensive editing to the English version by Laura Jana, Pediatrician, Social Entrepreneur & Connector of Dots; Leanne West, Chief Engineer of Pediatric Technology at Georgia Tech.
